Java HashMap 简介与工作原理¶
涉及以下问题:
- Hashmap的hash算法
- HashMap与HashTable的区别
- HashMap与HashTable的key能否为null?
- HashMap是如何存储null key的?
- hash冲突时如何解决
本文概要¶
链表和数组可以按照人们的意愿排列元素的次序。但若想查看某个指定的元素,却忘记了位置,就可能需要访问所有元素,直到找到为止。 大多数Java开发者都会用到Map,尤其是HashMap。使用HashMap可以简单高效地存取数据。
内部存储机制¶
HashMap实现了Map
- V put(K key, V value)
- V get(Object key)
- V remove(Object key)
- Boolean containsKey(Object key)
HashMap使用内部类Entry
- 对另一个entry的引用
next;用于实现链表linkedList的功能 - 代表key的hashValue的值
Java7中Entry类部分源码
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
…
}
Java8中同样用于辅助存储数据的还有树节点类TreeNode<K,V>
HashMap持有装载entry的数组table transient Node<K,V>[] table;。默认长度为16。首次使用时会初始化,必要时重新分配大小。长度是2的次方。数组table中存放的是LinkedList的头部或者二叉树的根节点。
也可以把这样的LinkedList称为bucket。
table的存储结构,利用链表
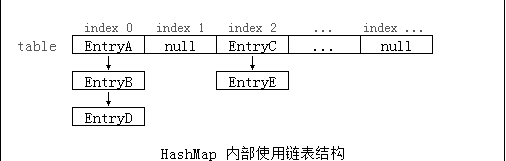
或者二叉树结构

当调用get或者put方法时,方法会计算出key对应的bucket存在table中的下标。然后去遍历list寻找目标key对象。使用key对象类的equals方法来判定对象是否相等。
对于get方法,若map中不存在相应的key,则返回null。
对于put(K key, V value)方法,若已经有value存在,则覆盖掉原来的value。如果不存在旧的value,则新建一个entry并存入。新的entry会成为对应bucket的头部。
那么bucket的下标是如何确定的呢?主要分为3个步骤:
- 第一步,获取key对象的hashcode;
- 第二步,根据第一步获得的hashcode,再散列一次(rehash)获得再散列值;这一步是为了防止所有的数据都被存放到table数组同一个地方;
- 第三步,使用再散列值与table数组当前长度减一进行位运算(bit-masks)。这一步保证了计算出来的下标不会超出table数组的范围。
Java7和Java8源码中计算table数组下标值的主要函数
// the "rehash" function in JAVA 7 that takes the hashcode of the key
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// the "rehash" function in JAVA 8 that directly takes the key
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// the function that returns the index from the rehashed hash
static int indexFor(int h, int length) {
return h & (length-1);
}
为了更高效,table数组的长度设定为2的次方。这与再散列后,indexFor方法的位运算有关。indexFor方法将下标限定在table数组的范围内。
如果数组长度length = 17,那么减一后得到16,二进制位为0…010000。与h进行位与运算后,只能得到0或1这两个下标值。这意味着长度为17的数组只使用了2个位置。
但如果数组长度为2的4次方,即16。在indexFor方法进行运算的是15,二进制位位0…001111。与运算后的到的结果范围是0到15,能完全利用到数组的位置。
自动扩容机制¶
为了防止内部数组中的链表过大过长,HashMap中有自动扩容的机制。主要是调整了内置数组table的大小。每次扩容操作会增大1倍。
从其中一个构造函数来看HashMap(int initialCapacity, float loadFactor),开发者可以定义初始大小和装载因数loadFactor。
数组默认的长度为16,装载因数默认为0.75。
每次执行put操作,会先检查是否需要扩充内置数组。为此,HashMap使用了2个数据:
- map的大小size。代表着map中存储的entry个数。每次添加或移除节点都会更新这个数字。
- 一个阈值:定义为数组长度乘以装载因数。扩容后会重新计算这个阈值。
添加entry前,检查size是否大于阈值。若满足大于阈值的条件,则重新创建一个2倍大小的新table数组。若创建了新table数组,会给当前所有的entry重新计算下标,放进新数组中。并抛弃原table数组。原来在同一个bucket(LinkedList)中的entry,重新计算下标后可能会被放到不同的位置上。

HashMap中并没有提供减小table数组的方法。
线程安全问题¶
我们知道,HashMap并不是线程安全的,它里面没有同步机制。
在扩容过程中,如果一个线程进行put或者get操作,此时计算得到的table的下标值可能就不对。更糟糕的情况是,若2个线程同时执行put方法,而此时HashMap判断需要进行自动扩容,map内部的LinkedList可能会产生环。那么调用get方法时,有可能会掉进死循环中。
而HashTable内置了同步机制。
从Java5开始,Java提供了适用于多线程环境的ConcurrentHashMap。
Java 7 ConcurrentHashMap使用了分段锁;Java 8使用了CAS。
key对象变化可能会造成数据丢失问题¶
对于HashMap来说,使用String或Integer来作为key是一个很好的实践。如果使用了自定义的类来作为key,修改了key的对象后有可能会造成丢失数据的问题。
key对象被修改后,它的hash值很可能会发生变化。HashMap中的entry并不能随之改变,存储的是上一次put操作的hash值。查询操作时很可能就找不到当初存放的那个value。
Java8对HashMap的改进¶
节点可以被转换成树节点TreeNode。使用红黑树结构来存放节点。查询时间是O(logn)。
table数组可以同时存储Node和TreeNode。
如果LinkedList节点数量超过8个,则转换成红黑树。
如果节点数量小于6个,则转换成链表。
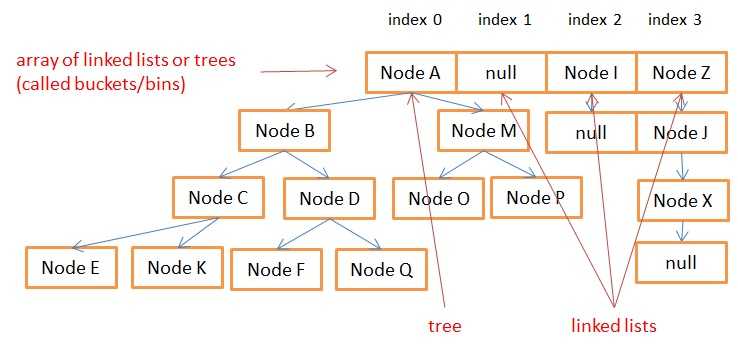
性能问题¶
分布是否均衡¶
HashMap根据key的hash值来计算出对应table数组的下标。比较好的情况是让元素能均匀地利用table数组。
可以在避免hash冲突的情况下,考虑复写hashCode方法和equals方法。尽可能利用table数组中的每一个位置。
自动扩容¶
如果要存储大量的数据,需要预估一下数据数量,选择一个合适的初始容量值。
存储大量数据的过程中会触发多次自动扩容。这些扩容过程需要消耗时间。
而如果初始设置的容量过大,则可能会浪费内存空间。
HashMap源码简介¶
映射表(Map)数据结构。映射表用来存放键值对。如果提供了键,就能查找到值。 Java类库为映射表提供了两个通用的实现:HashMap和TreeMap。这两个类都实现了Map接口。
HashMap采取的存储方式为:链表数组或二叉树数组。 散列映射表对键进行散列,数映射表的整体顺序对元素进行排序,并将其组织成搜索树。 散列或比较函数只能左右与键。与键关联的值不能进行散列或比较。
每当往映射表中添加或检索对象时,必须同时提供一个键。即通过Key查找Value。 键必须是唯一的。不能对同一个键存放两个值。如果对同一个键两次调用put方法,后一个值将会取代第一个值。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。 HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
下面是构造函数
public HashMap()
public HashMap(int initialCapacity)
public HashMap(int initialCapacity, float loadFactor)
// 包含 "子Map" 的构造函数
public HashMap(Map<? extends K, ? extends V> map)
HashMap 工作原理¶
- JDK 1.8
HashMap 继承 AbstractMap,实现了Map、Cloneable、java.io.Serializable接口
常量定义¶
默认容量必须是2的次方,这里是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
最大容量必须小于等于 1<<30 。若设置的容量大于最大容量,将其限制在最大容量。
static final int MAXIMUM_CAPACITY = 1 << 30;
超过此阈值,将某个元素的链表结构转换成树结构
static final int TREEIFY_THRESHOLD = 8;
小于等于此阈值,将二叉树结构转换成链表结构
static final int UNTREEIFY_THRESHOLD = 6;
状态变量¶
已存储的键值对数量,map中有多少个元素
transient int size;
当存储的数量达到此值后,需要重新分配大小(capacity * load factor)
int threshold;
此HashMap的结构被修改的次数
transient int modCount;
存储数据的数组。必要时会重新分配空间。长度永远是2的次方。不需要序列化。
它的长度会参与存入元素索引的计算。假设长度n为默认的16,那么通过(n - 1) & hash计算得到的索引范围是[0, 15]
装载节点的数组table。首次使用时会初始化,必要时重新分配大小。长度是2的次方。
transient Node<K,V>[] table;
table的存储结构,利用链表
或者二叉树结构
链表结构和二叉树结构会根据实际使用情况互相转换。具体参见UNTREEIFY_THRESHOLD与TREEIFY_THRESHOLD。
构造函数¶
带容量和装载因子的构造函数。检查输入的容量值,将其限制在0到最大容量之间。检查装载因子。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
方法介绍¶
获取key对象的hash值¶
获取key对象的hash值,将其高位与低位进行亦或(XOR)计算。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
创建一个常规节点
// Create a regular (non-tree) node
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
初始化或让table的尺寸放大一倍
final Node<K,V>[] resize()
LinkedHashMap用的回调
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
put(K key, V value)方法流程¶
调用put方法时,发生了什么?
添加键值对的方法。重点看putVal方法。将尝试插入的键值对暂时称为目标元素。
* 检查table实例是否存在,获取table的长度
* 检查输入的hash值,计算得到索引值
* 若table中对应索引值中没有元素,插入新建的元素
* 检查当前是否需要扩充容量
* 尝试更新现有的元素
* 若使用了二叉树结构,调用二叉树节点类的插入方法putTreeVal
* 遍历内部元素,插入新值或更新原有值
* 检查是否要扩大存储空间
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* @param onlyIfAbsent 若为true,则不改变已有的值
* @param evict 若为false,table处于创建状态
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
实例 HashMap<String, String>初始化并调用put方法
HashMap<String, String> strMap = new HashMap<>();
strMap.put("one", "value");
strMap.put("two", "value");
strMap.put("three", "value");
System.out.println("hash(\"one\") = " + hash("one"));
System.out.println("hash(\"two\") = " + hash("two"));
System.out.println("hash(\"three\") = " + hash("three"));
/*
hash("one") = 110183
hash("two") = 115277
hash("three") = 110338829
*/
"one"的hash值是110183,通过(n - 1) & hash计算存储索引。
默认容量n=16,计算得到索引是7。以此类推。
get 方法流程¶
计算输入key对象的hash值,根据hash值查找。 若map中不存在相应的key,则返回null。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
从源码中学到的实用方法¶
hash优化函数,“扰动函数”
public static int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
大于且最接近输入值的2的次方数
/**
* Returns a power of two size for the given target capacity.
* MAXIMUM_CAPACITY 是上限
*/
public static int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap与HashTable的区别¶
相同点:
HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
HashMap是非线程安全的,多线程环境下可以采用concurrent并发包下的concurrentHashMap。
HashMap 实现了Serializable接口,支持序列化;也实现了Cloneable接口,能被克隆。
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。 Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。 Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
区别:
1、继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
2、线程安全性不同
javadoc中关于hashmap的一段描述如下:此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。
在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。
HashMap与HashTable的key能否为null?¶
HashMap对象的key、value值均可为null。 HashTable对象的key、value值均不可为null。
HashTable对为空的key和value做了处理,会抛出NullPointerException
HashMap是如何存储null key的?¶
hashMap是根据key的hashCode计算出索引值来寻找存放位置的。若key为null,hash值记为0;然后继续插入方法。
hash冲突时HashMap如何处理¶
HashMap中维护着Node数组Node<K,V>[],其中的Node是链表节点或者是二叉树节点。
如果发生hash冲突,计算出来的数组下标是同一个。新增的节点会加入该位置的链表或二叉树中。
参考¶
- 《Java核心技术 卷1 基础知识(原书第9版)》
- Java HashMap 工作原理 - coding-geek
- Java
TreeMap简介与分析 https://www.ibm.com/developerworks/cn/java/j-lo-tree/index.html